ECE421: Introduction to Machine Learning
In the Fall 2022, this course is taught by:
- Section 0101: Dr. Nicolas Papernot (University of Toronto and Vector Institute)
- Section 0102: Mohammad Yaghini (University of Toronto and Vector Institute)
The videos below were recorded by Dr. Papernot but are applicable to both sections of the course.
You will find below a playlist of videos recorded for this course. Click on the video thumbnail to play it and/or maximize it. Next to each video, you can find either the slides or notes that I used to record the video. You can also find a list of optional reading. I voluntarily selected lots of reading options to allow you to explore different authors and find an exposition of machine learning that best matches your background and preparation for this course. You do not have to read all book chapters pointed out or watch all videos linked to in the reading list, but this should help you find a style of material that works best for you, which you can use to help you better understand the content of my video recordings for this course.
Background material: this is a list of links (list being populated) to help you refresh some of the background material required to understand the content of the following videos on ML
Tutorial material: this is a list of links to notes that will serve as the basis for tutorials this semester.
- Linear Algebra
- Multivariate Differentiation
- Lagrange Multiplier
- JAX tutorial (part 1)
- JAX tutorial part 2 will be revealed on Piazza to not spoil the first part
Interactive demos: this is a list of links to interactive demos that will help you form an intuition for algorithms we cover in this course.
Introduction
#1: What is a ML task? Slides
An introduction to what distinguished machine learning from more traditional computer programs. Brief discussion of the different forms of ML: unsupervised, supervised, and reinforcement learning.
Optional reading and online material on this topic:
Part 1: Machine learning basics
Unsupervised learning
#2: What is unsupervised learning? Slides
An introduction to unsupervised learning. Includes examples of clustering, dimensionality reduction, and data visualization. These three applications are motivate the two techniques presented in the rest of the module.
Optional reading and online material on this topic:
#3 - Clustering with the k-means algorithm Notes
An introduction the the k-means algorithm, with the cluster assignment and centroid update steps. Concludes with an example showing how data that does not contain well-separated clusters opens up a few questions on the solutions found by the k-means algorithm. These are addressed in the next video.
Optional reading and online material on this topic:
#4 - Distortion in the k-means algorithm Notes
The objective function behind the k-means algorithm allows us to choose better strategies for initializing the cluster centroids. We also go over two strategies for picking the number k of centroids the k-means algorithm is looking for.
Optional reading and online material on this topic:
#5 - Principal Component Analysis Notes
This video covers PCA for dimensionality reduction. How to use SVD to perform PCA? How to compute the reconstruction error of PCA? How to choose the number of components?
https://stats.stackexchange.com/a/140579Optional reading and online material on this topic:
Supervised learning with linear models
#6 - Linear regression Notes
Supervised learning, linear regression, mean squared loss, direct solution through critical points
Optional reading and online material on this topic:
#7 - Vectorization Notes
How to vectorize linear regression over multiple features per input? Also introduces the matrix notation required to perform linear regression over an entire data (vectorization across multiple examples) and compute the average cost over the data.
Optional reading and online material on this topic:
#8 - What is linearly classifiable? Notes
How to turn a linear regression model into a binary linear classification model using a threshold function? How to visualize simple binary functions (e.g., not, and, xor) in input and weight spaces to forge an intuition as to why they are linearly separable (e.g., not, and) or why they are not linearly separable (e.g., xor)?
Optional reading and online material on this topic:
- [de Freitas] Logistic regression (some of the material in this link will be more clear later on in the course)
- [Bishop] Chapters 4.1.1
- [Shalev-Shwartz & Ben-David] Chapter 9.1
#9 - Why is XOR not linearly separable? Notes
A more in depth treatment of the non-linearly separable nature of XOR using a proof by contradiction and notions of convexity.
#10 - Perceptron Learning Rule Notes
How to use the perceptron learning rule to set the weights of a binary linear classifier?
Optional reading and online material on this topic:
- [Bishop] Chapters 4.1.7
- [Hastie et al.] Chapter 4.5.1
- [Murphy] Chapter 8.5.4
- [Shalev-Shwartz & Ben-David] Chapter 9.1.2
#11 - Support Vector Machines Notes
Geometric interpretation of the max-margin hyperplane, max-margin as an optimization problem.
Optional reading and online material on this topic:
Part 2: Tackling non-linearly separable data
Adapting linear models to non-linear data
#12 - Doing more with linear models through feature extraction Notes
Polynomial feature mappings for linear regression, under/overfitting, hyperparameters, generalization
Optional reading and online material on this topic:
- [Bishop] Chapters 1.1
- [Murphy] Chapter 7.2
- [Shalev-Shwartz & Ben-David] Chapter 11
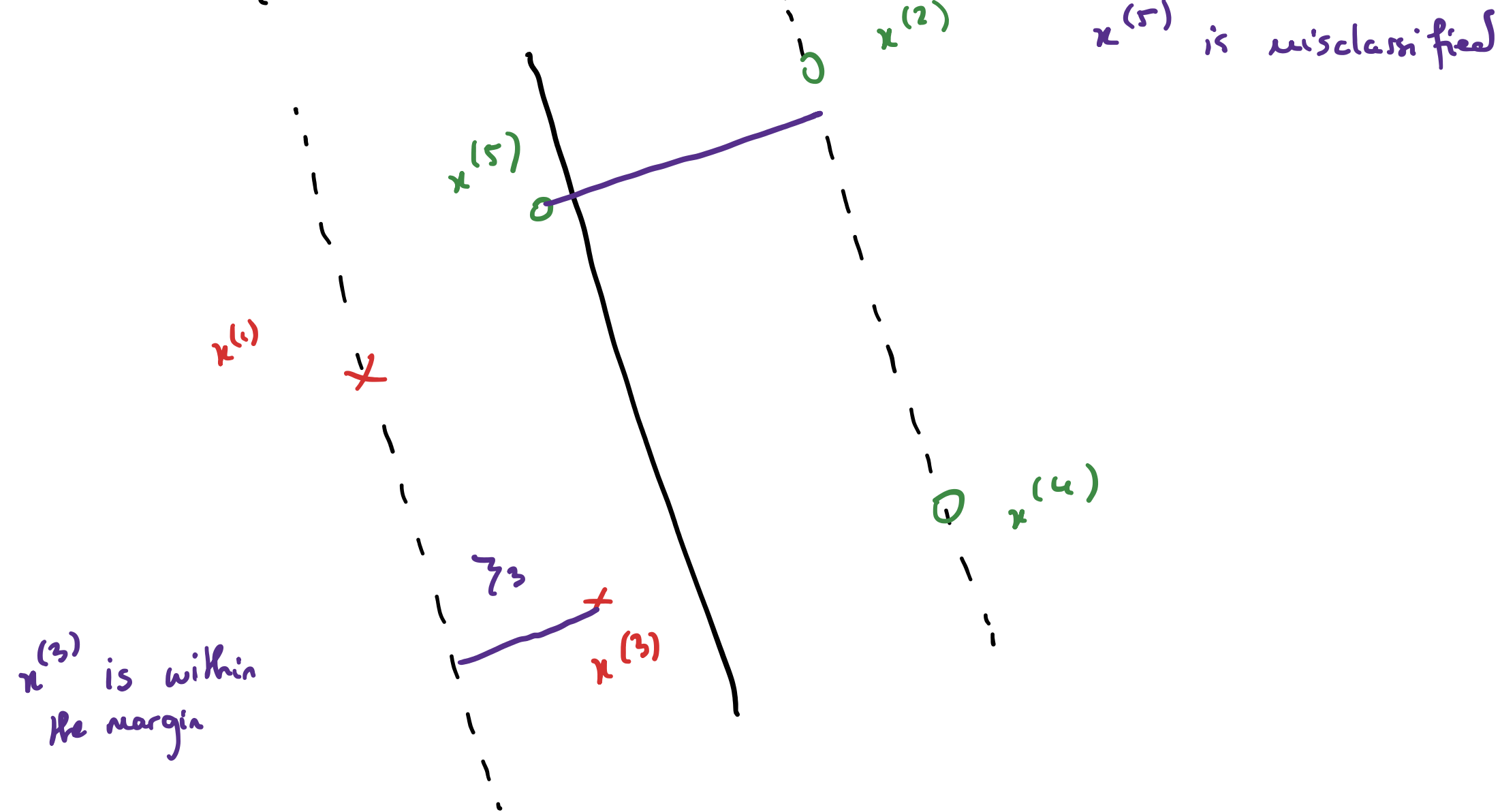
#13 - Slack variables for SVMs Notes
Slack variables for SVMs on non linearly separable data or data that contains outliers.
Optional reading and online material on this topic:
#14 - Kernels for SVMs Notes
Intuition for kernels based on similarity between points, Gaussian kernels, implications of hyperparameter choice for under/over fitting.
Optional reading and online material on this topic:
Minimizing losses with gradient descent
#15 - Gradient descent for linear regression Notes
Introduces the concept of steepest descent to optimize iteratively the values of model parameters with the help of a loss funciton. Update rule for gradient descent explained with linear regression and least squares.
Optional reading and online material on this topic:
- [Bishop] Chapter 5.2.4
- [Hastie et al.] Chapter 10.10.1
- [Murphy] Chapter 8.3.2
- [Shalev-Shwartz & Ben-David] Chapter 14.1
#16 - Maximum likelihood interpretation of least squares Notes
An interpretation of the least squares loss in the context of linear regression, based on maximum likelihood.
Optional reading and online material on this topic:
- [Bishop] Chapter 1.2.{4-5}
- [Murphy] Chapter 7.3
#17 - Losses for linear classification Notes
Compares the 0-1 loss, least squared error, and cross-entropy. Also introduces the logistic function as an activation function.
Optional reading and online material on this topic:
#18 - Gradient descent on the cross-entropy loss Notes
Introduces logistic cross entropy to avoid the numerical instabilities in cross entropy loss applied to logistic regression. Full derivation of the update rule for gradient descent on a logistic regression for regression and classification.
Optional reading and online material on this topic:
- [Bishop] Chapter 4.3.2
- [Murphy] Chapter 3.5.3
#19 - Multiclass classification Notes
Generalization of a binary classifier to the multiclass setting, introduction of the softmax activation and the multiclass variant of cross-entropy.
Optional reading and online material on this topic:
Part 3: Deep learning basics
Deep neural networks
#20 - Feedforward neural networks Notes
Introduces the concepts of layers (composition of abstractions), activation functions, and the multilayer perceptron. Also illustrates the expressive power of a deep neural network on xor.
Optional reading and online material on this topic:
#21 - Expressive power Notes
Introduces the concept of expressive power for a deep neural network and the universal approximation theorem. Outlines how expressive power stems from activation functions and depth rather than width.
Optional reading and online material on this topic:
- [Hastie et al.] Chapter 11.2
- [Murphy] Chapter 16.5 and 28.3
Backpropagating through deep neural networks
#22 - Backpropagation Notes
Intuition behind backpropagation based on the chain rule. Introduces the concepts of a computational graph, forward and backward passes, and the backpropagation algorithm itself. Examples on linear regression and a multilayer neural network (with and without vectorized notation).
Optional reading and online material on this topic:
#23 - Local minima in deep learning Notes
Counter-argument for why deep learning is not convex, and how to deal with saddle points, plateaux, and ravines with optimizers that take into account curvature. Finishes with a discussion of how to tune a learning rate.
Optional reading and online material on this topic:
#24 - Stochastic gradient descent Notes
Introduces the concept of minibatch sampling and stochastic gradient descent (SGD)
Optional reading and online material on this topic:
- [Bishop] Chapter 5.2.4
- [Murphy] Chapter 8.5
- [Shalev-Shwartz & Ben-David] Chapter 14.3-5
Generalization in deep learning
#25 - Generalization in practice Notes
Overfitting, train/validation/test splits. Qualitative training/test curves as a function of the number of training examples, number of parameters, and number of epochs.
Optional reading and online material on this topic:
- [Bishop] Chapter 2
- [Murphy] Chapter 1.4.8
- [Shalev-Shwartz & Ben-David] Chapter 2
#26 - Bias-variance decomposition Notes
Bayes error (minimal risk), and bias-variance decomposition, visualization and connection to underfitting and overfitting.
Optional reading and online material on this topic:
- [Bishop] Chapter 3.2
- [Murphy] Chapter 6.4.4
- [Shalev-Shwartz & Ben-David] Chapter 5.2
#27 - Improving generalization: a bag of tricks Notes
Introduces techniques for reducing overfitting in neural network training: data augmentation, decreasing the number of parameters, weight decay, early stopping, ensembles, dropout.
Optional reading and online material on this topic:
Part 4: Architectures for deep learning
Convolutional Neural networks
#28 - Convolution operation Notes
Introduction to the convolution operation and layer.
Optional reading and online material on this topic:
#29 - Convolutional architectures Notes
Building blocks for convolutional neural networks: convolutional layer, pooling layers. Examples of convolutional neural networks on Mnist and Imagenet.
Optional reading and online material on this topic:
Language modeling with deep learning
#30 - Backpropagation through time Notes
Recurrent architectures, backpropagation through time.
Optional reading and online material on this topic:
#31 - Sequence modeling and neural machine translation Notes
Language modeling, neural machine translation with encoder-decoder architectures.
Optional reading and online material on this topic:
#32 - Attention Notes
Attention-based models for machine translation.
Optional reading and online material on this topic:
#33 - Long Short-Term Memory Notes
How gradients can explode or vanish when training RNNs with backpropagation through time. Solutions with gradient clipping and the LSTM architecture.
Optional reading and online material on this topic:
Deep residual networks
#34 - Deep Residual Networks Notes
Optional reading and online material on this topic:
Acknowledgments. Material used in this course is adapted from several prior iterations of similar courses taught by others. This includes CSC321 by Prof. Grosse and Coursera's ML course by Prof. Ng.